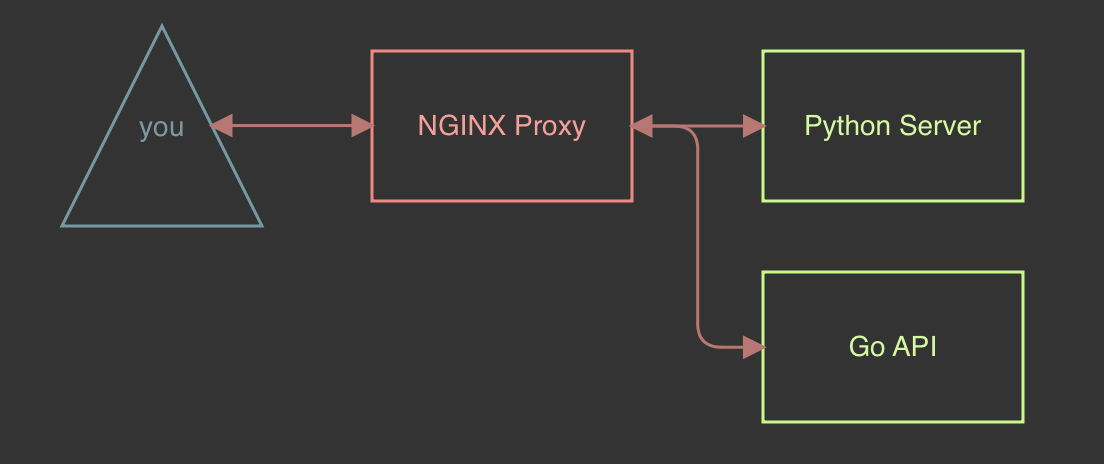
In part one of this blog series, we set up a NGINX proxy and took the first steps in creating our web testing environment. The next piece of infrastructure we will be building is a web directory we can use for directory enumerations and discovery. To do this we will be using a python simple HTTP server. Once we are done, we will deploy that server behind our proxy.
Required Software:
- python3
- dirb
- gobuster
- docker & docker-compose
Python Web Servers
Python web servers grant quick access to web servers, as long as python is installed a web server can be easily stood up to host files. For the rest of these exercises, we will assume that you have python3 installed. In this section, we will build a simple web directory to conduct our tests on. Start by creating a new directory within the web-test folder we started our project in called python-web, and within that folder create a `html` folder. That change will give us a web working directory that looks like the below:
web-test ├── docker-compose.yml ├── nginx/ │ ├── cache/ │ ├── cert/ │ │ ├── cert.pem │ │ └── key.pem │ ├── error.log │ └── nginx.conf └── python-web/ └── html/
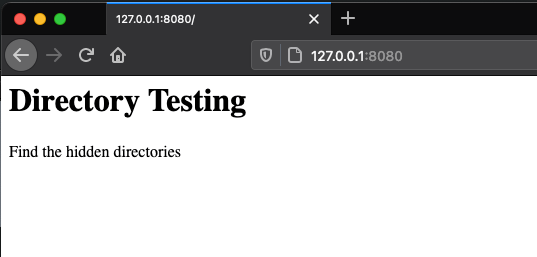
Let’s make an index.html file that contains the following content within the html folder so that we can verify that everything is working once we start our server.
<html>
<body>
<h1>Directory Testing</h1>
<p>Find the hidden directories</p>
</body>
</html>Now we can test out our web server by changing our terminal directory to the html folder we created and running the command python3 -m http.server 8080. Open a web browser and navigate to http://127.0.0.1:8080. We should be able to see our newly created files contents.
Since we can now verify that our html file is displayed on our python web server, we can start building out more of our web directory. Within the html folder, create the directories img, js, and hidd3n1 to start with. Let’s also create the files robots.txt, admin-xlogin.html, admin-blog.html, and finally a flag.txt file within the hidd3n1 directory. Afterward, we will now have a working directory that looks like this:
web-test ├── docker-compose.yml ├── nginx/ │ ├── cache/ │ ├── cert/ │ │ ├── cert.pem │ │ └── key.pem │ ├── error.log │ └── nginx.conf └── python-web/ └── html/ ├── admin-blog.html ├── admin-xlogin.html ├── hidd3n1/ │ └── flag.txt ├── img/ ├── index.html ├── js/ └── robots.txt
With a fully built out web root, we now have all of the targets we will need to start enumerating directories and files on that web server. The last thing we will do is add the following content to the robots.txt file:
User-agent: *
Disallow: hidd3n1/This file can usually be found in some web roots to prevent web crawlers requesting content from specific areas of your website. Not all sites have this file, but when they do, that file might reveal sensitive files, or areas normally accessible like the hidd3n1 directory listed in our file.
Enumerating A Web Root
Now that we have a web directory and functional web server, let’s start enumerating its contents and see what we can find.
For this we can use a few methods, assuming there are links on the page we can start by looking at where the links lead to, but since this is just flat with no links, we will need to utilize wordlists to try to determine what is present on the web server. To make this easier we can use tools such as dirb or gobuster. For the rest of these exercises, we will be using both of these tools to compare their outputs and how they interact with the python web server.
For the wordlists, I find that I favor the git repository SecLists when it comes to wordlists, in particular the wordlist in that directory Discovery/Web-Content/big.txt. Next, we are comparing the outputs of both dirb and gobuster and seeing what we get back using big.txt.
Dirb Output:
dirb http://127.0.0.1:8080 big.txt
-----------------
DIRB v2.22
By The Dark Raver
-----------------
START_TIME: Wed Mar 17 00:59:46 2021
URL_BASE: http://127.0.0.1:8080/
WORDLIST_FILES: big.txt
-----------------
GENERATED WORDS: 20462
---- Scanning URL: http://127.0.0.1:8080/ ----
+ http://127.0.0.1:8080/img (CODE:301|SIZE:0)
+ http://127.0.0.1:8080/js (CODE:301|SIZE:0)
+ http://127.0.0.1:8080/robots.txt (CODE:200|SIZE:33)Gobuster Output:
gobuster dir -u http://127.0.0.1:8080 -t 5 -s 200,301 -w big.txt -x html
===============================================================
Gobuster v3.0.1
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@_FireFart_)
===============================================================
[+] Url: http://127.0.0.1:8080
[+] Threads: 5
[+] Wordlist: big.txt
[+] Status codes: 200,301
[+] User Agent: gobuster/3.0.1
[+] Extensions: html
[+] Timeout: 10s
===============================================================
2021/03/17 01:00:45 Starting gobuster
===============================================================
/Index.html (Status: 200)
[ERROR] 2021/03/17 01:01:10 [!] Get http://127.0.0.1:8080/gaestebuch.html: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
[ERROR] 2021/03/17 01:01:10 [!] Get http://127.0.0.1:8080/galaxy.html: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
[ERROR] 2021/03/17 01:01:10 [!] Get http://127.0.0.1:8080/gaisbot.html: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
[ERROR] 2021/03/17 01:01:10 [!] Get http://127.0.0.1:8080/galerie.html: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
[ERROR] 2021/03/17 01:01:10 [!] Get http://127.0.0.1:8080/galera: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
[ERROR] 2021/03/17 01:01:21 [!] Get http://127.0.0.1:8080/hint.html: read tcp 127.0.0.1:49196->127.0.0.1:8080: read: connection reset by peer
/img (Status: 301)
/index.html (Status: 200)
/js (Status: 301)
/robots.txt (Status: 200)
[ERROR] 2021/03/17 01:01:42 [!] Get http://127.0.0.1:8080/screenshots.html: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
[ERROR] 2021/03/17 01:01:42 [!] Get http://127.0.0.1:8080/script_library: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
[ERROR] 2021/03/17 01:01:42 [!] Get http://127.0.0.1:8080/script.html: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
[ERROR] 2021/03/17 01:01:43 [!] Get http://127.0.0.1:8080/searches.html: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
[ERROR] 2021/03/17 01:01:43 [!] Get http://127.0.0.1:8080/searchpreview.html: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
===============================================================
2021/03/17 01:01:59 Finished
===============================================================Looking at the outputs in our web server, we can see this is very noisy and will generate a lot of traffic in the web logs. Below, we get a glimpse at what someone might notice if directory enumeration is being carried out on their web server.
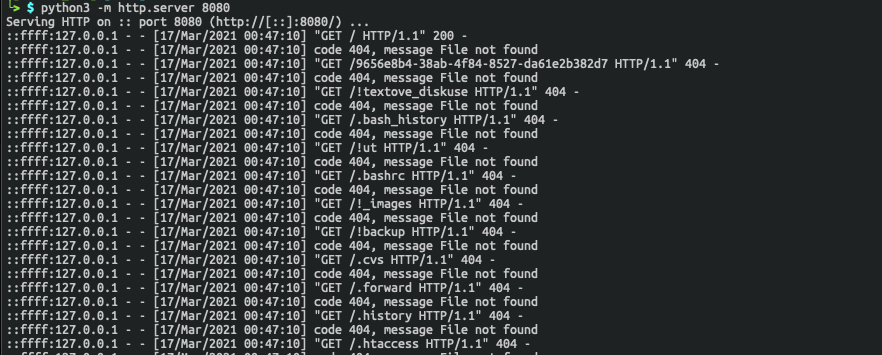
Taking a look at our outputs, the first characteristic that stands out is that dirb looks a lot cleaner and does not result in error messages. This is mostly due to the web server we are using; it’s getting overwhelmed by the number of calls targeting our server. This is something that should be considered when initiating a scan, our goal for this is to enumerate the directory and not create a denial-of-service situation. If we run our gobuster command again with a single thread we will notice a lot less errors this time around, but we do end up with similar results.
gobuster dir -u http://127.0.0.1:8080 -t 1 -s 200,301 -w big.txt -x html
===============================================================
Gobuster v3.0.1
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@_FireFart_)
===============================================================
[+] Url: http://127.0.0.1:8080
[+] Threads: 1
[+] Wordlist: big.txt
[+] Status codes: 200,301
[+] User Agent: gobuster/3.0.1
[+] Extensions: html
[+] Timeout: 10s
===============================================================
2021/03/17 19:51:54 Starting gobuster
===============================================================
/Index.html (Status: 200)
[ERROR] 2021/03/17 19:52:20 [!] Get http://127.0.0.1:8080/fusion.html: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
/img (Status: 301)
/index.html (Status: 200)
/js (Status: 301)
/robots.txt (Status: 200)
[ERROR] 2021/03/17 19:52:56 [!] Get http://127.0.0.1:8080/shaken: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
===============================================================
2021/03/17 19:53:13 Finished
===============================================================Going back to the dirb results, we also notice that it did not pick up the .html files since we did not specify a wordlist, but by doing that we will no longer be able to discover the folders as shown below:
-----------------
DIRB v2.22
By The Dark Raver
-----------------
START_TIME: Wed Mar 17 01:17:46 2021
URL_BASE: http://127.0.0.1:8080/
WORDLIST_FILES: big.txt
EXTENSIONS_LIST: (.html) | (.html) [NUM = 1]
-----------------
GENERATED WORDS: 20462
---- Scanning URL: http://127.0.0.1:8080/ ----
+ http://127.0.0.1:8080/Index.html (CODE:200|SIZE:104)
+ http://127.0.0.1:8080/index.html (CODE:200|SIZE:104)
-----------------
END_TIME: Wed Mar 31 07:11:35 2021
DOWNLOADED: 20462 - FOUND: 2But what about the other files that did not get detected?
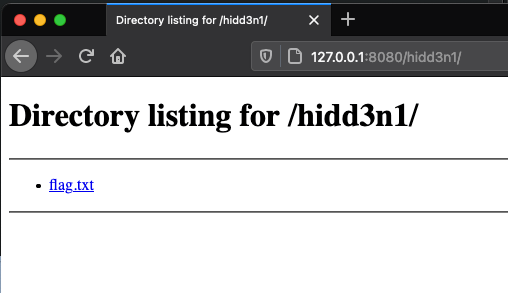
We can still find those files too, but we will just have to try harder to get those. The potentially easy win for us on this one is to check the robots.txt in the root of the directory to see if anything was called out. That will let us know that hidd3n1/ is possibly a directory and if we go there, we will see our flag.txt.
Crafting A Custom Wordlist
That will leave us with admin-blog.html and admin-xlogin.html to discover. These values are not present within the wordlists we are using, but their pieces are. To speed this up, let’s use the following short.txt list. Alternatively, we could create a new list using the previously used wordlists, but that will create a much larger file that will take forever to get through. Ideally, this would be built based on words from the site or guessed based on the URLs present on the site, but since we don’t have that – we will use the list below and common words.
short.txt
admin xlogin blog index access
Using short.txt, we can now combine it with itself to make our new list, and between each word we will add a – to separate the words. This can be done with the below commands and will have the following contents:
for i in $(cat short.txt); do for k in $(cat short.txt); do echo "$i-$k" >> combined-short.txt;done;done;
cat combined-short.txt
admin-admin
admin-xlogin
admin-blog
admin-index
admin-access
xlogin-admin
xlogin-xlogin
xlogin-blog
xlogin-index
xlogin-access
blog-admin
blog-xlogin
blog-blog
blog-index
blog-access
index-admin
index-xlogin
index-blog
index-index
index-access
access-admin
access-xlogin
access-blog
access-index
access-accessWith our new list, we can use it to identify the remaining files within that directory.
dirb http://127.0.0.1:8080 combined-short.txt -X .html
-----------------
DIRB v2.22
By The Dark Raver
-----------------
START_TIME: Thu Mar 18 07:48:56 2021
URL_BASE: http://127.0.0.1:8080/
WORDLIST_FILES: combined-short.txt
EXTENSIONS_LIST: (.html) | (.html) [NUM = 1]
-----------------
GENERATED WORDS: 25
---- Scanning URL: http://127.0.0.1:8080/ ----
+ http://127.0.0.1:8080/admin-xlogin.html (CODE:200|SIZE:0)
+ http://127.0.0.1:8080/admin-blog.html (CODE:200|SIZE:0)
-----------------
END_TIME: Thu Mar 18 07:48:56 2021
DOWNLOADED: 25 - FOUND: 2Dockerizing A Server
Let’s build this into the rest of our existing docker-compose setup by building a Dockerfile to host our web directory. Make a Dockerfile in our python-web directory that contains the configuration below. This will create a folder to host our files and set the working directory to that folder so that when a python server is started in our container that folder will be hosted. Don’t worry about adding in our directory yet, we will be setting that within our docker-compose.yml file and using NGINX to make our web directory accessible.
RUN mkdir /html
WORKDIR /html
CMD python -m http.server 8080The next step is to update our docker-compose.yml to build and create a volume that will host our local version of the web root in the /html directory on the container. We will also be adding it to the webapps network to keep locked down to the docker network so that we can expose it throughout NGINX proxy.
python-web:
build: ./python-web/
restart: always
volumes:
- ./python-web/html:/html
networks:
- webappsBy default, python will start a web server on port 8000. After adding the following lines below to our nginx.config, we should see our index.html file when we go to https://127.0.0.1/ after we build and start our file.
location / {
proxy_pass http://web-test_python-web_1:8080;
}Now our directory structure should look something like this:
web-test ├── docker-compose.yml ├── nginx/ │ ├── cache/ │ ├── cert/ │ │ ├── cert.pem │ │ └── key.pem │ ├── error.log │ └── nginx.conf └── python-web/ ├── Dockerfile └── html/ ├── admin-blog.html ├── admin-xlogin.html ├── hidd3n1/ │ └── flag.txt ├── img ├── index.html ├── js └── robots.txt
And have a nginx.conf and a docker-compose.yml that look like this:
nginx.conf
events {
}
http {
error_log /etc/nginx/error_log.log warn;
client_max_body_size 20m;
proxy_cache_path /etc/nginx/cache keys_zone=one:500m max_size=1000m;
server {
listen 443 ssl;
ssl_certificate /cert/cert.pem;
ssl_certificate_key /cert/key.pem;
ssl_session_timeout 5m;
ssl_protocols TLSv1.2;
ssl_ciphers AES256:!ECDHE:!All;
ssl_prefer_server_ciphers on;
location / {
proxy_pass http://web-test_python-web_1:8080;
}
}
}docker-compose.yml
version: '3'
services:
nginx:
image: nginx:stable
restart: always
volumes:
- ./nginx/nginx.conf:/etc/nginx/nginx.conf
- ./nginx/error.log:/etc/nginx/error_log.log
- ./nginx/cache/:/etc/nginx/cache
- ./nginx/cert:/cert
ports:
- 443:443
networks:
- webapps
python-web:
build: ./python-web/
restart: always
volumes:
- ./python-web/html:/html
networks:
- webapps
networks:
webapps:
driver: bridgeAfter running docker-compose build it will start the process of building out the python server’s container. After running docker-compose up we should now see your index.html when we go to https://127.0.0.1 and should see our index.html file.
Enabling Rate Limiting
With everything built within our docker-compose environment, let’s configure some rate limiting so that we don’t overload our server and also make it more difficult to enumerate directories. For this, we are going to need to go back to our nginx.conf and specify a limit_req_zone and a limit_req. The first line we will be adding is the limit_req_zone which will go just above our server declaration. This configuration is responsible for limiting remote hosts accessing our server to 5 requests per second within a 5-minute interval. Keep in mind, a lot of these will not stop someone from enumerating your web server, but will definitely slow things down for someone attempting to enumerate a web server.
limit_req_zone $binary_remote_addr zone=ip:5m rate=5r/s;The next line we will be adding is limit_req, which we will set to use our zone, allowing up to 10 requests, and will start delaying requests after 5 requests are made. This will go in our location declaration we have pointed towards our python server.
limit_req zone=ip burst=10 delay=5;If you wish to do a deeper dive on these settings and some others that could be implemented, the blog post from nginx.com goes into each option in more detail. With those lines added, we should now have a nginx.conf that looks like the below:
events {
}
http {
error_log /etc/nginx/error_log.log warn;
client_max_body_size 20m;
proxy_cache_path /etc/nginx/cache keys_zone=one:500m max_size=1000m;
limit_req_zone $binary_remote_addr zone=ip:5m rate=5r/s;
server {
listen 443 ssl;
ssl_certificate /cert/cert.pem;
ssl_certificate_key /cert/key.pem;
ssl_session_timeout 5m;
ssl_protocols TLSv1.2;
ssl_ciphers AES256:!ECDHE:!All;
ssl_prefer_server_ciphers on;
location / {
limit_req zone=ip burst=12 delay=8;
proxy_pass http://web-test_python-web_1:8080;
}
}
}Enumerating With Limitations
After restarting our docker instances again using docker-compose, let’s try gobuster again and see if we get the same errors. This time we will notice something different, we will get no results using gobuster.
gobuster dir -u https://127.0.0.1 -k -t 5 -s 200,301 -w big.txt -x html
===============================================================
Gobuster v3.0.1
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@_FireFart_)
===============================================================
[+] Url: https://127.0.0.1
[+] Threads: 5
[+] Wordlist: big.txt
[+] Status codes: 200,301
[+] User Agent: gobuster/3.0.1
[+] Extensions: html
[+] Timeout: 10s
===============================================================
2021/03/24 06:57:40 Starting gobuster
===============================================================
===============================================================
2021/03/24 06:58:52 Finished
===============================================================After looking back at docker-compose we see why, after gobuster hit that threshold, future requests started returning 503 errors instead of 200 and 301 like they were previously seeing.
503 errors:
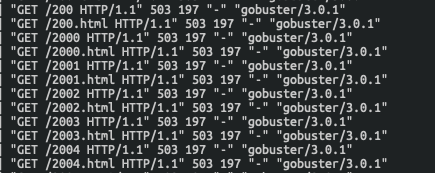
Now let’s check dirb and see what it finds on our web server. Right away we notice one big difference, it actually returns back directories and files. This is primarily due to dirb not executing concurrent requests like gobuster, which will let it remain under our threshold (but will take longer).
dirb https://127.0.0.1 big.txt -X .html
-----------------
DIRB v2.22
By The Dark Raver
-----------------
START_TIME: Wed Mar 24 07:00:59 2021
URL_BASE: https://127.0.0.1/
WORDLIST_FILES: big.txt
EXTENSIONS_LIST: (.html) | (.html) [NUM = 1]
-----------------
GENERATED WORDS: 20462
---- Scanning URL: https://127.0.0.1/ ----
+ https://127.0.0.1/Index.html (CODE:200|SIZE:104)
+ https://127.0.0.1/index.html (CODE:200|SIZE:104)
[TRUNCATED]The End Of Part 2
With this piece added, we now have an environment where we can manipulate ciphers, enumerate web roots for files and directories, and also control the rate at which content hits our server to mitigate those trying to enumerate our web root. In the next blog, we will continue to add to our dockerized obstacle course, by rounding off our initial build plan with a final container hosting an API built in go. Hope you enjoyed this blog and see you in the next one.
Here is Part 1 if you missed it!